使用Python抓取数据
Whark
3月 27, 2018
本文以律师行业信用服务平台为例,介绍如何对页面数据进行提取,保存。
开始:页面数据分析
打开 广东省律师行业信用信息服务平台 ,F12打开控制台,点击Network,刷新界面,发现了向API请求的接口,返回的资源是 Json 格式的,而且资源中的数据就是页面上的,就能确认页面中的律师信息就是通过这个接口读取的,本站点是采用前后端分离写的,如果没有类似的请求,数据是直接渲染在HTML中,说明HTML在后端已经处理好了,只能按标签,分离数据了。
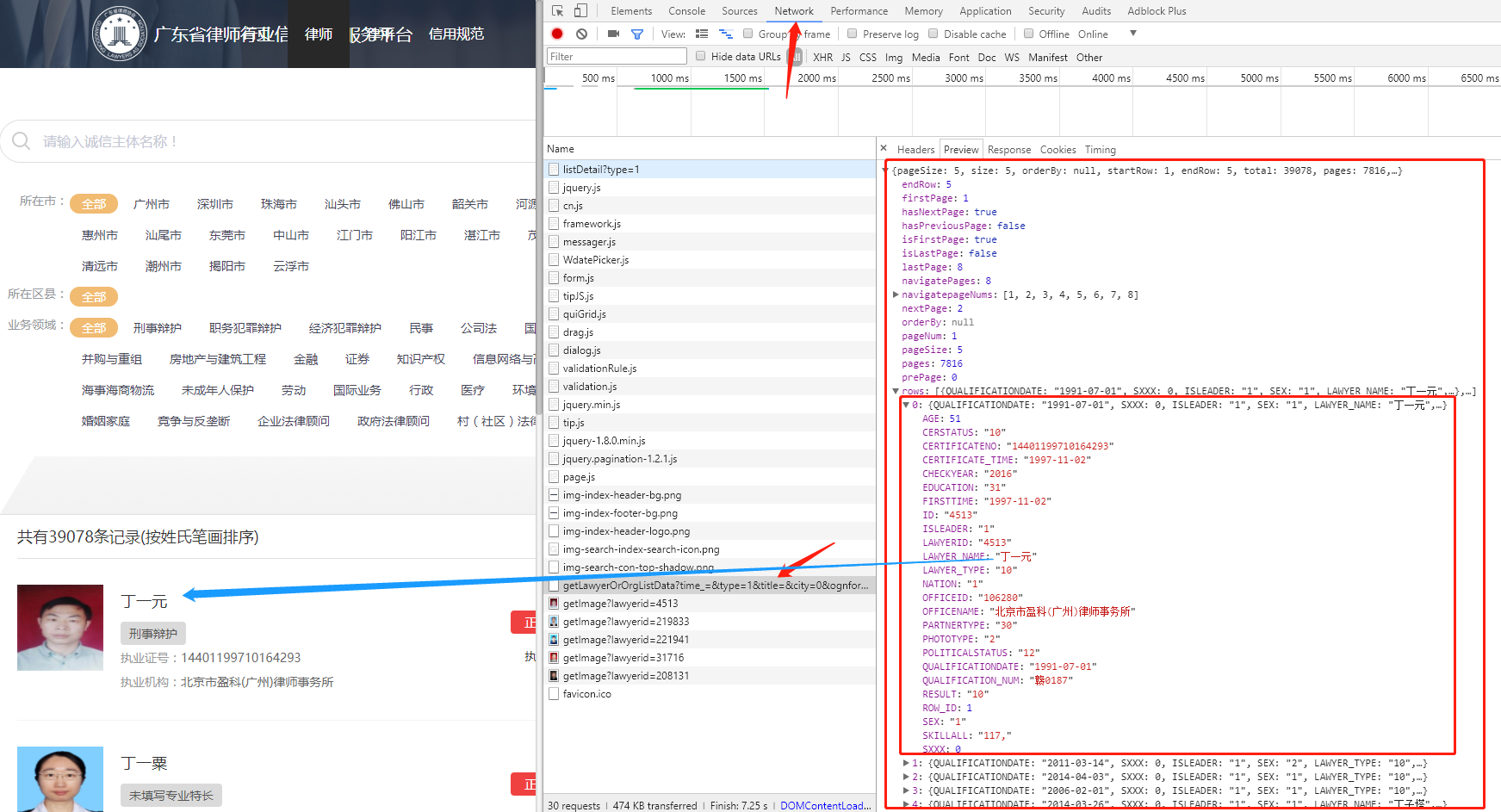
尝试:API接口调用
看看API能不能正常访问,如下图:
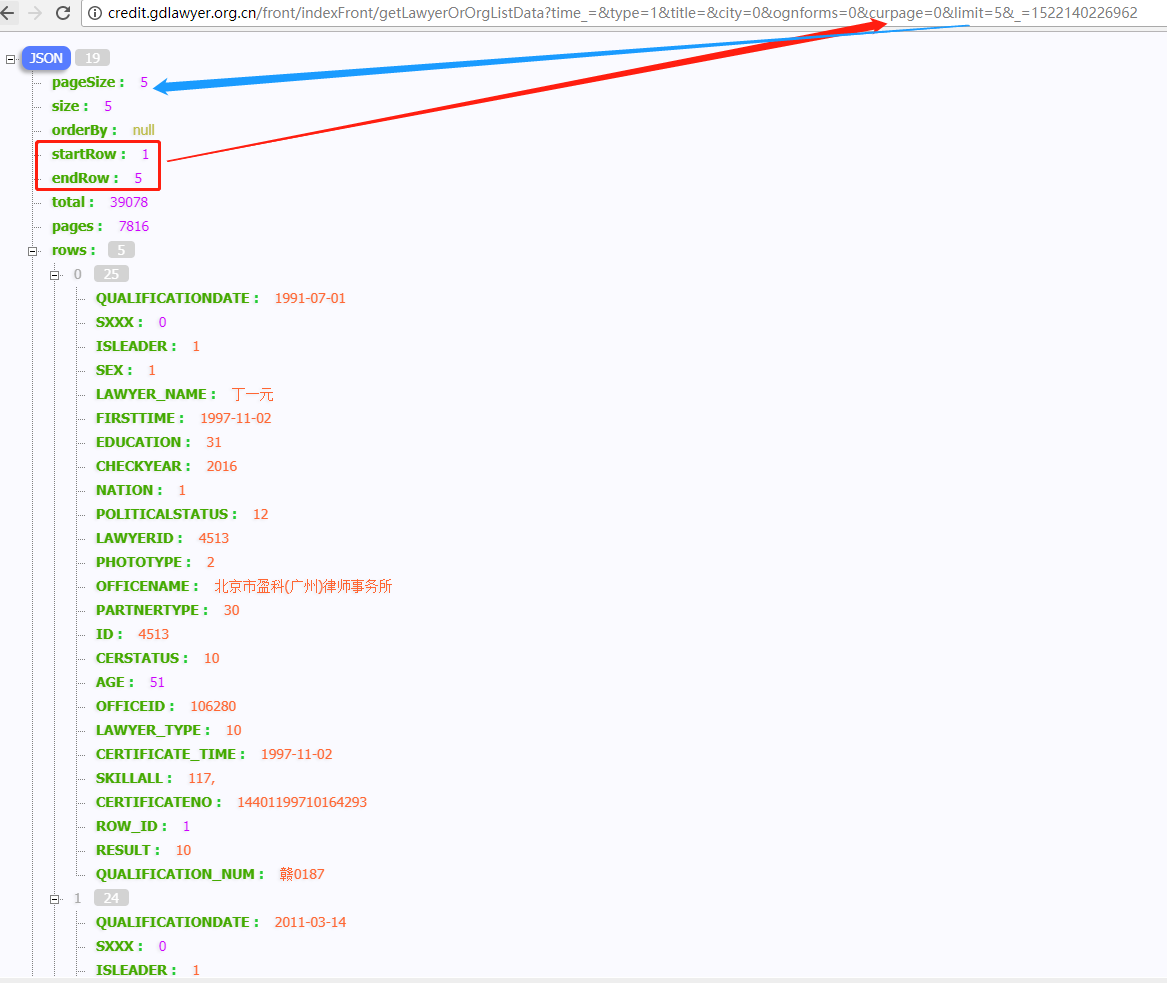
观察参数,发现参数就是筛选项、分页大小、偏移量、和13位的时间戳。
把参数含义弄明白后,使用Python来请求API数据
import requests
result = requests.get('http://credit.gdlawyer.org.cn/front/indexFront/getLawyerOrOrgListData?time_=&type=1&title=&city=0&ognforms=0&curpage=0&limit=2&_=1522140226962')
print(result.text)
运行的结果如下:
<?xml version="1.0" encoding="utf-8"?>
<page-info start-row="1" is-last-page="false" has-next-page="true" first-page="1" pages="7816" has-previous-page="false" size="5" pre-page="0" is-first-page="true" end-row="5" next-page="2" navigate-pages="8" last-page="8" page-num="1" page-size="5" total="39078">
<rows xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:java="http://java.sun.com" empty="false" xsi:type="java:java.util.HashMap" />
<rowsxmlns:xsi xmlns:java="http://java.sun.com" empty="false" xsi:type="java:java.util.HashMap" />
<rows xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:java="http://java.sun.com" empty="false" xsi:type="java:java.util.HashMap" />
<rows xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:java="http://java.sun.com" empty="false" xsi:type="java:java.util.HashMap" />
<rows xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:java="http://java.sun.com" empty="false" xsi:type="java:java.util.HashMap" />
<navigatepage-nums>1</navigatepage-nums>
<navigatepage-nums>2</navigatepage-nums>
<navigatepage-nums>3</navigatepage-nums>
<navigatepage-nums>4</navigatepage-nums>
<navigatepage-nums>5</navigatepage-nums>
<navigatepage-nums>6</navigatepage-nums>
<navigatepage-nums>7</navigatepage-nums>
<navigatepage-nums>8</navigatepage-nums>
</page-info>
发现并不是之前在浏览器中看到的JSON格式,而是xml格式的,所以可能是Header中没有指定接受json格式,所以添加一下Header:
import requests
s = requests.Session()
headers = {'Accept' : 'application/json;charset=utf-8'}
s.headers.update(headers)
result = s.get('http://credit.gdlawyer.org.cn/front/indexFront/getLawyerOrOrgListData?time_=&type=1&title=&city=0&ognforms=0&curpage=0&limit=2&_=1522140226962')
print(result.text)
加了一个Accept的Header就好了,返回结果如下:
{
"pageSize": 2,
"size": 2,
"orderBy": null,
"startRow": 1,
"endRow": 2,
"total": 39078,
"pages": 19539,
"rows": [
{
"QUALIFICATIONDATE": "1991-07-01",
"SXXX": 0,
"ISLEADER": "1",
"SEX": "1",
"LAWYER_NAME": "丁一元",
"FIRSTTIME": "1997-11-02",
"EDUCATION": "31",
"CHECKYEAR": "2016",
"NATION": "1",
"POLITICALSTATUS": "12",
"LAWYERID": "4513",
"PHOTOTYPE": "2",
"OFFICENAME": "北京市盈科(广州)律师事务所",
"PARTNERTYPE": "30",
"ID": "4513",
"CERSTATUS": "10",
"AGE": 52,
"OFFICEID": "106280",
"LAWYER_TYPE": "10",
"CERTIFICATE_TIME": "1997-11-02",
"SKILLALL": "117,",
"CERTIFICATENO": "14401199710164293",
"ROW_ID": 1,
"RESULT": "10",
"QUALIFICATION_NUM": "赣0187"
},
{
"QUALIFICATIONDATE": "2011-03-14",
"SXXX": 0,
"ISLEADER": "1",
"SEX": "2",
"LAWYER_TYPE": "10",
"CERTIFICATE_TIME": "2015-11-20",
"LAWYER_NAME": "丁一粟",
"FIRSTTIME": "2015-11-20",
"CERTIFICATENO": "14403201511624464",
"EDUCATION": "14",
"CHECKYEAR": "2016",
"ROW_ID": 2,
"NATION": "3",
"POLITICALSTATUS": "12",
"LAWYERID": "219833",
"PHOTOTYPE": "2",
"OFFICENAME": "北京大成(深圳)律师事务所",
"PARTNERTYPE": "30",
"ID": "219833",
"CERSTATUS": "10",
"RESULT": "10",
"QUALIFICATION_NUM": "A20104301040236",
"AGE": 38,
"OFFICEID": "102020"
}
],
"firstPage": 1,
"prePage": 0,
"nextPage": 2,
"lastPage": 8,
"isFirstPage": true,
"isLastPage": false,
"hasPreviousPage": false,
"hasNextPage": true,
"navigatePages": 8,
"navigatepageNums": [
1,
2,
3,
4,
5,
6,
7,
8
],
"pageNum": 1
}
数据处理
至此,就能想想数据怎么存储了,返回的数据中 “total”: 39078 ,说明总共有39079条数据,可以设置分页大小,可以按照100条一次进行处理,先抓取第一页,看看数据总量是多少,然后再确认分页数,正式进行爬取,输出每一行数据中的律师的姓名,代码如下:
import requests
import xmltodict, json
import time, math
import random
s = requests.Session()
headers = {'Accept' : 'application/json;charset=utf-8'}
s.headers.update(headers)
resu = s.get('http://credit.gdlawyer.org.cn/front/indexFront/getLawyerOrOrgListData?time_=&type=1&title=&city=0&ognforms=0&curpage=0&limit=1&_=' + str(round(time.time() * 1000)))
data = json.loads(resu.text)
total = data['total']
limit = 100
page = math.ceil(total / limit)
print(limit)
print(page)
for curPage in range(page):
resu = s.get('http://credit.gdlawyer.org.cn/front/indexFront/getLawyerOrOrgListData?time_=&type=1&title=&city=0&ognforms=0&curpage=' + str(curPage) + '&limit=' + str(limit) + '&_=' + str(round(time.time() * 1000)))
# Json to dist
data = json.loads(resu.text)
# 律师数据
rows = data['rows']
# 遍历数据
for value in rows:
print(value['LAWYER_NAME'])
# 每抓取1页,随机等待几秒
wait_time = random.choice(range(1,10))
time.sleep(wait_time)
结果如下:
100
391
丁一元
丁一粟
丁上第
丁义平
丁子塔
丁小栩
丁小媚
...
这些数据访问都正常了之后,就可以用使用数据库存储下来了,首先建库建表,挑了一些关键信息进行存储
数据表结构如下:
CREATE TABLE `lawyer` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
`sex` tinyint(2) DEFAULT NULL,
`qualification_date` varchar(10) DEFAULT NULL,
`first_time` varchar(10) DEFAULT NULL,
`checkyear` int(11) DEFAULT NULL,
`education` varchar(10) DEFAULT NULL,
`office_name` varchar(255) DEFAULT NULL,
`certificate_no` bigint(20) DEFAULT NULL,
`qualification_num` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1152 DEFAULT CHARSET=utf8mb4;
完整代码如下,添加了部分统计代码:
import requests
import xmltodict, json
import pymysql
import time, math, datetime
import random
# Mysql数据库连接
db = pymysql.connect("127.0.0.1","root","xxxxxx","lawyar",use_unicode=True,charset="utf8")
# 使用 cursor() 方法创建一个游标对象 cursor
cursor = db.cursor()
s = requests.Session()
headers = {
'Accept' : 'application/json;charset=utf-8'
}
s.headers.update(headers)
resu = s.get('http://credit.gdlawyer.org.cn/front/indexFront/getLawyerOrOrgListData?time_=&type=1&title=&city=0&ognforms=0&curpage=0&limit=1&_=' + str(round(time.time() * 1000)))
# Json to dist
data = json.loads(resu.text)
total = data['total']
limit = 100
page = math.ceil(total / limit)
print("数据总量:" + str(total))
print("总页数:" + str(page))
print("预计总执行时间:%ss" % (str(total/9)))
# 总时间
start = datetime.datetime.now()
count_wait_time = 0
for curPage in range(page):
resu = s.get('http://credit.gdlawyer.org.cn/front/indexFront/getLawyerOrOrgListData?time_=&type=1&title=&city=0&ognforms=0&curpage=' + str(curPage) + '&limit=' + str(limit) + '&_=' + str(round(time.time() * 1000)))
# Json to dist
data = json.loads(resu.text)
# 律师数据
rows = data['rows']
# 遍历数据
for value in rows:
sql = "INSERT INTO `lawyer`(`name`, `sex`, `qualification_date`, \
`first_time`, `checkyear`, `education`, `office_name`, `certificate_no`, `qualification_num`) \
VALUES ('%s','%s','%s','%s','%s','%s','%s','%s','%s')" % \
(value.get('LAWYER_NAME'), value.get('SEX'), value.get('QUALIFICATIONDATE'), value.get('FIRSTTIME'), \
value.get('CHECKYEAR'), value.get('EDUCATION'), value.get('OFFICENAME'), value.get('CERTIFICATENO'), value.get('QUALIFICATION_NUM'))
sql = sql.replace('\'None\'', '0')
sql.encode('utf-8')
# print(sql)
cursor.execute(sql)
# 提交数据到数据库
db.commit()
wait_time = random.choice(range(1,10))
count_wait_time += wait_time
print("当前第%d页,等待%ds" % (curPage, wait_time))
time.sleep(wait_time)
# 关闭数据库连接
db.close()
print("数据保存完毕,总执行时间:%ss,总等待时间:%ds" % (str(datetime.datetime.now() - start), count_wait_time))
以下是我将total手动定义为560时的执行结果:
数据总量:560
总页数:6
预计总执行时间:62.22222222222222s
当前第0页,等待4s
当前第1页,等待6s
当前第2页,等待5s
当前第3页,等待2s
当前第4页,等待8s
当前第5页,等待8s
数据保存完毕,总执行时间:0:01:12.207355s,总等待时间:33s
总结
前后端分离的网站,都能使用这种方式爬取数据,如果数据在HTML中,就只能使用爬虫了,近期如果有时间,再出一篇爬虫的文章。